
Big Data Analytics: How Business Leaders Can Turn Data into Actionable Strategies
Recommendation systems drive personalized experiences on platforms like Netflix and Amazon, influencing what users see next based on their past behaviours. These systems aren’t just tools; they’re critical for engagement, retention, and business growth.
In this guide, you’ll learn the fundamentals of constructing a recommendation system using FastAI within Microsoft Fabric. We'll explore how to implement Collaborative Filtering, a technique that drives recommendations by identifying patterns in user behaviour. Following a practical, straightforward approach, we'll work with a widely used Movie Rating dataset to demonstrate how to create personalized experiences on Microsoft Fabric. This hands-on tutorial is designed to be efficient, giving you the tools to build and deploy your own recommendation system with ease.
Many of the concepts and techniques in this tutorial draw inspiration from the renowned Practical Deep Learning for Coders course. By the end of this guide, you’ll have the skills to create a powerful recommendation engine capable of analyzing data and generating tailored suggestions for users. Let’s dive in and get started.
In this blog, you will find:
💡 What is a Recommendation System?
🚀 Why Use FastAI and Microsoft Fabric?
📋 Step-by-Step Guide to Building a Recommendation System with FastAI and Microsoft Fabric
What is a Recommendation System?
A recommendation system is a machine learning model designed to predict and suggest relevant items to users based on their preferences or behavior. This type of system analyzes past interactions, such as movie ratings, product purchases, or browsing habits, and uses this information to make personalized suggestions. There are various types of recommendation systems, with the two most common approaches being Collaborative Filtering and Content-Based Filtering.
.png?width=930&height=466&name=What%20is%20a%20Recommendation%20System%20(2).png)
In this tutorial, we focus on Collaborative Filtering, a widely-used method that identifies similarities between users and items. By recognizing users with comparable behaviours or preferences, the system can suggest items that these users have liked. This technique is extensively employed in streaming services, e-commerce, and social media to maintain user engagement through personalized recommendations.
Why Use FastAI and Microsoft Fabric?
FastAI is a deep learning library built on top of PyTorch, designed to simplify the development of machine learning models. It removes much of the complexity involved in building sophisticated models, allowing even non-experts to create powerful systems with minimal coding. FastAI offers a high-level API for working with different types of data, including collaborative filtering, making it an ideal choice for building a recommendation engine.
On the other hand, Microsoft Fabric is a robust, cloud-based platform that provides a scalable infrastructure for machine learning tasks. By using Fabric, you can easily train, deploy, and manage machine learning models in a production environment. Its seamless integration with tools like MLflow enables efficient tracking and versioning of your models, ensuring that you can optimize and refine them as needed. Together, FastAI and Microsoft Fabric offer a streamlined process for building and deploying scalable recommendation systems.
Step-by-Step Guide to Building a Recommendation System with FastAI and Microsoft Fabric
Now that we’ve covered how these tools work together, let’s move on to the practical steps of creating your machine learning model.
Create a Machine Learning (ML) Model
First, we need to set up a new machine learning model in Microsoft Fabric. Navigate to the Data Science section of Fabric and select "Create ML Model." For this tutorial, we’ll be building a movie recommendation system, so let’s name the model Recommender.
Once the model is created, select the option to start with a new notebook. This notebook will serve as the environment where you will write the code to train and test your model.
Train Your Model
Now that the model is set up, it’s time to train it. We’ll use a standard movie recommendation dataset for this purpose. In your notebook, install the necessary libraries such as FastAI and MLflow to handle the training process.
Each section can be its own cell in your notebook.
Install and import requirements:
!pip install -U -q fastai recommenders
from fastai.collab import *
from fastai.tabular.all import *
import mlflow
import mlflow.fastai
set_seed(42)
Load a movie ratings dataset from FastAI
path = untar_data(URLs.ML_100k)
!ls {path}
Retrieve the u1.base data which will be used for training and validation.
ratings_df = pd.read_csv(path/'u1.base', delimiter='\t', header=None,
names=['user','movie','rating','timestamp'])
# convert IDs to strings to prevent confusion with embeddings
ratings_df['user'] = ratings_df['user'].astype('str')
ratings_df['movie'] = ratings_df['movie'].astype('str')
ratings_df.head()
Create our dataloader from the ratings dataframe.
data = CollabDataLoaders.from_df(ratings_df,
user_name='user',
item_name='movie',
rating_name='rating',
bs=64)
data.show_batch()
Train our model and save it to mlFlow. Feel free to play with the number of factors, the weight decay, number of epochs and learning rate.
mlflow.fastai.autolog()
with mlflow.start_run():
learn = collab_learner(data, n_factors=50, y_range=[0,5.5], wd=1e-1)
learn.fit_one_cycle(5, lr_max=5e-3)
After running all the above cells, you should see something like this as the output of the final cell:
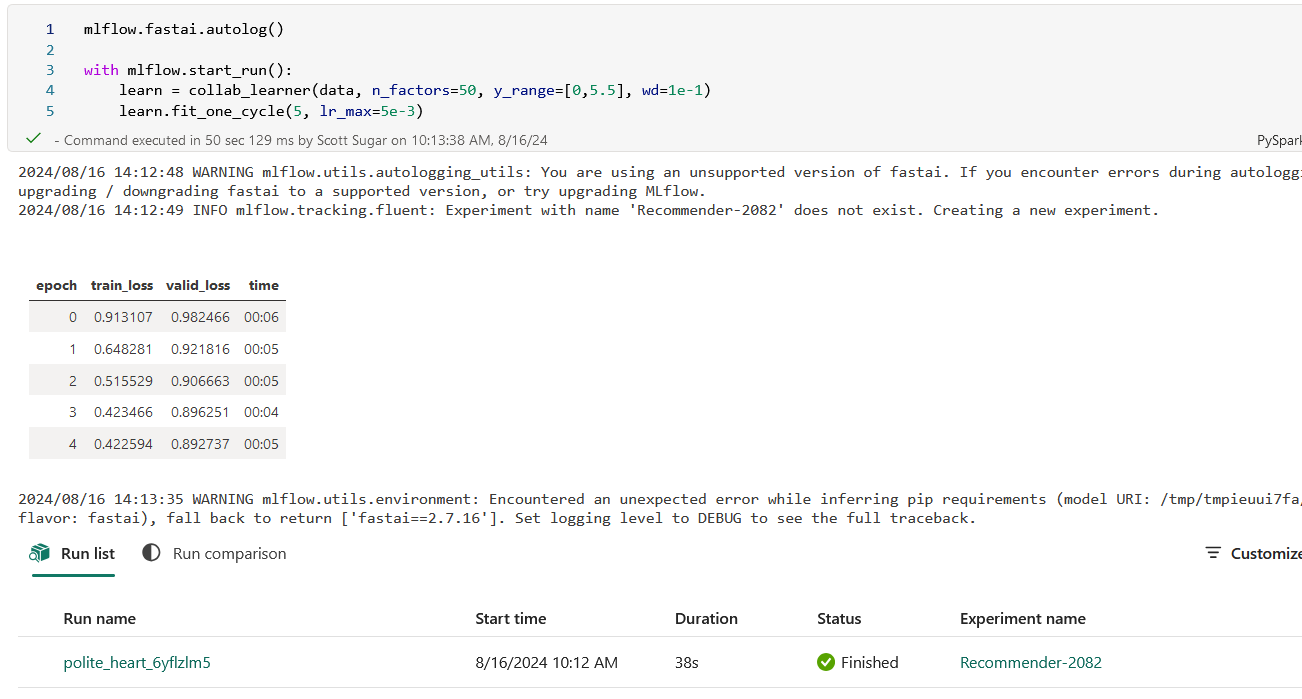
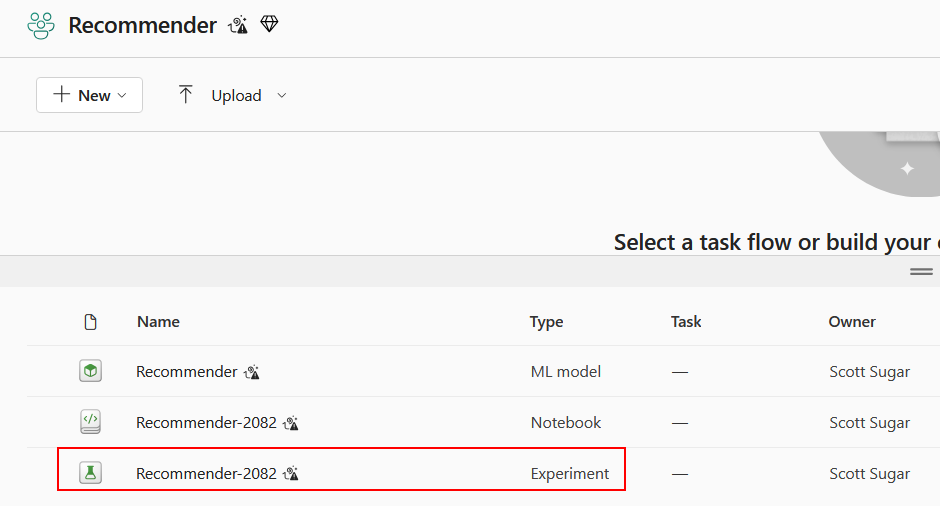
You should also see a new Experiment in your workspace (you may need to refresh your browser window):
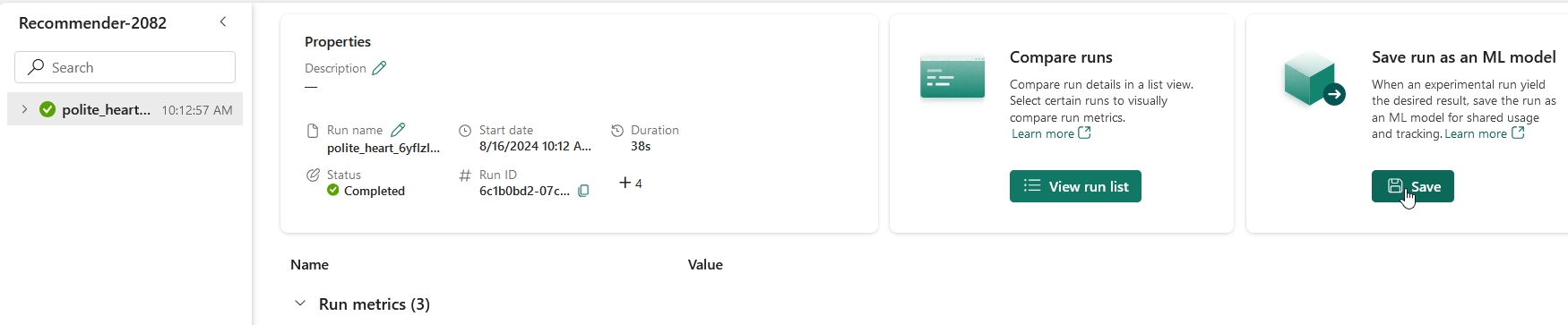
Save Your ML Model
Once the training is done, it’s important to save your model for future use. In your Fabric workspace, navigate to the newly created experiment and click on Save run as ML model.
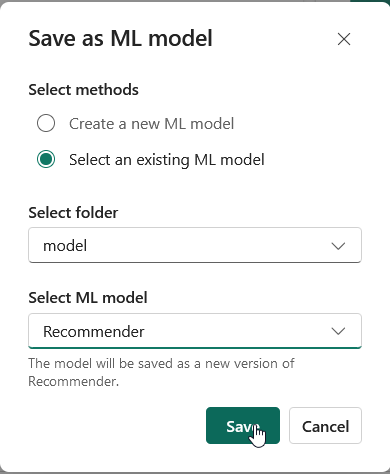
From the available options, select an existing ML model, choose the folder where your model will be stored, and hit Save.
Load and Predict
To test your model and make predictions, create a new notebook in your workspace. Install the required libraries once again and load your saved model.
Install and import requirements
!pip install -U -q fastai recommenders
from fastai.tabular.all import *
from recommenders.models.fastai.fastai_utils import score
Next, let's reload the data. We'll bring in the same data used for training and validation, plus an additional test set. This will help us list the users from the training and validation data and identify the movies they haven't seen (or rated) yet. We'll also grab the movie names to make things easier to understand later on.
path = untar_data(URLs.ML_100k)
!ls {path}
Load the movie ids and names
#read in the movies data for use later
movies = pd.read_csv(path/'u.item', delimiter='|', encoding='latin-1',
usecols=(0,1),
names=('movie','title'),
header=None)
movies['movie'] = movies['movie'].astype('str')
movies.head()
Retrieve the original data we used for training and validation so we can see what the users haven’t seen (i.e. rated) yet.
#retrieve the u1.base data which will be used for training/validation
ratings_df = pd.read_csv(path/'u1.base', delimiter='\t', header=None,
names=['user','movie','rating','timestamp'])
# make sure the IDs are loaded as strings to better prevent confusion with embedding ids
ratings_df['user'] = ratings_df['user'].astype('str')
ratings_df['movie'] = ratings_df['movie'].astype('str')
ratings_df.head()
Read in the testing data set we’ll run predictions on.
#retrieve the u1.test data which will be used for running predictions
test_df = pd.read_csv(path/'u1.test', delimiter='\t', header=None,
names=['user','movie','rating','timestamp'])
# make sure the IDs are loaded as strings to better prevent confusion with embedding ids
test_df['user'] = test_df['user'].astype('str')
test_df['movie'] = test_df['movie'].astype('str')
test_df.head()
Load our saved model
import mlflow
learner = mlflow.fastai.load_model(model_uri=f"models:/Recommender/latest")
Run predictions for the entire test data set
#retrieve all users and items from the dataloader
total_users, total_items = learner.dls.classes.values()
#remove the first element of each array - will be #na, and convert to dataframes
total_users = pd.DataFrame(np.array(total_users[1:], dtype=str), columns=['user'])
total_items = pd.DataFrame(np.array(total_items[1:], dtype=str), columns=['movie'])
#get the unique set of users from the testing data which we will run predictions for
test_users = pd.DataFrame(test_df['user'].unique(), columns=['user'])
#only include users that exist in both the testing and the training dataset (otherwise we will receive an error when scoring/predicting for users that don't exist in the training data).
test_users = test_users.merge(total_users, how='inner')
#build a 2D array that lists all possible items for each test user
users_items = test_users.merge(total_items, how='cross')
#join user_items dataframe back to the original ratings dataframe and only keep items that the user hasn't rated yet (i.e. rating is null)
test_data = pd.merge(users_items, ratings_df.astype(str), on=['user', 'movie'], how='left')
test_data = test_data[test_data['rating'].isna()][['user', 'movie']]
#Score the testing data to retrieve back predictions
top_k_scores = score(learner,
test_df=test_data,
user_col='user',
item_col='movie',
prediction_col='prediction')
#join predictions to movies dataframe to include additional movie information in the prediction (title, genres)
predictions = pd.merge(top_k_scores, movies, left_on='movie', right_on='movie', how='left')
#return all predictions for the test users
predictions
Result from the notebook should look like this:
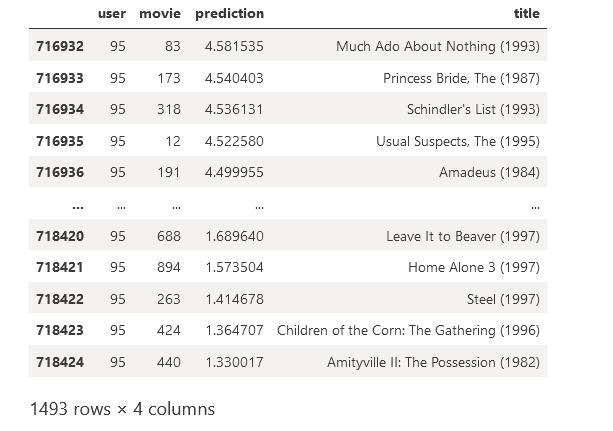
Test predictions for a single user
user = '95'
predictions[predictions['user'] == user]
You are all done! With the model trained and deployed, your recommendation system is ready to start delivering personalized suggestions to users.
Conclusion
Building a recommendation system using FastAI on Microsoft Fabric is an efficient way to deliver personalized content to users. This guide showed how to set up a model, train it using collaborative filtering, and generate movie recommendations based on user preferences. By leveraging the power of FastAI for model training and Microsoft Fabric for scalability and deployment, you can create recommendation engines that are both robust and highly adaptable. With the tools and knowledge from this guide, you're well on your way to implementing recommendation systems that enhance user engagement and satisfaction.
You may be interested in these blogs:
💰 Efficient Cost Management with Copilot for PowerBI: A Complete Guide
📈 Power BI Usage Metrics Across All Workspaces: Step-by-Step
📊 How AI Data Analysis Enhances Analytics: Key Benefits & Top Tools
📓 Installing the ArcGIS Python Module in a Fabric Notebook: Step-by-Step
Next Steps: Explore 'Fabric and Copilot' Recordings
Dive deeper into Microsoft Fabric and uncover the full spectrum of its capabilities. Explore how this powerful platform enables organizations to efficiently manage, analyze, and harness valuable data and insights.

By signing up for Copilot Virtual Briefing Sessions, you’ll get exclusive access to a treasure trove of information, including the “Fabric and Copilot” recording. Join Scott Sugar as he dives into the details of Fabric, showing how Copilot can transform your data analysis workflows and boost your decision-making. Register now to unlock the full potential of Microsoft Fabric and take your data transformation journey to the next level.

From the 1980's, when his father used to hand down old computer equipment, to now, Scott Sugar has always had a fascination with technology. The ability to communicate with people, regardless of distance or location, is, in Scott's opinion, one of the best things about tech. With over 20 years of experience in the IT industry, and 17 years at ProServeIT, Scott's areas of expertise include data & analytics, and IT operations, monitoring, and alerting. Scott heads up ProServeIT's Ho Chi Minh City, Vietnam office. He has spent the majority of his adult life in Asia, and speaks 3 languages.



Comments